
Summary -
In this topic, we described about the below sections -
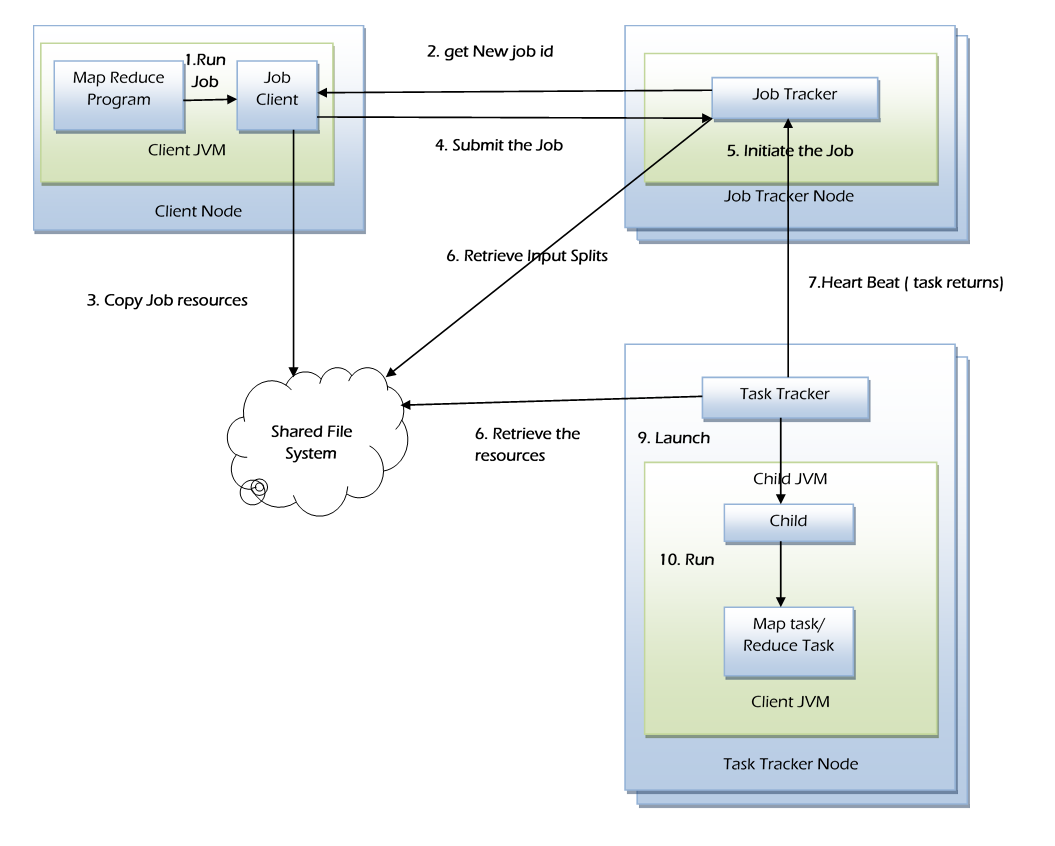
MapReduce is a programming model designed to process large amount of data in parallel by dividing the job into several independent local tasks. Running the independent tasks locally reduces the network usage drastically. To run the tasks locally, the data needs move to the data nodes for data processing.
The below tasks occur when the user submits a MapReduce job to Hadoop -
- The local Job Client prepares the job for submission and hands it off to the Job Tracker.
- The Job Tracker schedules the job and distributes the map work among the Task Trackers for parallel processing.
- Each Task Tracker issues a Map Task.
- The Job Tracker receives progress information from the Task Trackers.
- Once the mapping phase results available, the Job Tracker distributes the reduce work among the Task Trackers for parallel processing.
- Each Task Tracker issues a Reduce Task to perform the work.
- The Job Tracker receives progress information from the Task Trackers.
- Once the Reduce task completed, Cleanup task will be performed.
The following are the main phases in map reduce job execution flow -
- Job Submission
- Job Initialization
- Task Assignment
- Task Execution
- Job/Task Progress
- Job Completion
Job Submission -
The job submit method creates an internal instance of JobSubmitter and calls submitJobInternal method on it. waitForCompletion method samples the job’s progress once a second after the job submitted.
waitForCompletion method performs below -
- It goes to Job Tracker and gets a jobId for the job
- Perform checks if the output directory has been specified or not.
- If specified checks the directory already exists or is new and throws error if any issue occurs with directory.
- Computes input split and throws error if it fails because the input paths don’t exist.
- Copies the resources to Job Tracker file system in a directory named after Job Id.
- Finally, it calls submitJob method on JobTracker.
Job Initialization -
Job tracker performs the below steps in job initialization -
- Creates object to track tasks and their progress.
- Creates a map tasks for each input split.
- The number of reduce tasks is defined by the configuration mapred.reduce.tasks set by setNumReduceTasks method.
- Tasks are assigned with task ID’s.
- Job initialization task and Job clean up task created and these are run by task trackers.
- Job clean up tasks which delete the temporary directory after the job is completed.
Task Assignment -
Task Tracker sends a heartbeat to job tracker every five seconds. The heartbeat is a communication channel and indicate whether it is ready to run a new task. The available slots information also sends to them.
The job allocation takes place like below -
- Job Tracker first selects a job to select the task based on job scheduling algorithms.
- The default scheduler fills empty map task before reduce task slots.
- The number of slots which a task tracker has depends on number of cores.
Task Execution -
Below steps describes how the job executed -
- Task Tracker copies the job jar file from the shared filesystem (HDFS).
- Task Tracker creates a local working directory and un-jars the jar file into the local file system.
- Task Tracker creates an instance of TaskRunner.
- Task Tracker starts TaskRunner in a new JVM to run the map or reduce task.
- The child process communicates the progress to parent process.
- Each task can perform setup and cleanup actions based on OutputComitter.
- The input provided via stdin and get output via stdout from the running process even if the map or reduce tasks ran via pipes or socket in case of streaming.
Job/Task Progress -
Below steps describes about how the progress is monitored of a job/task -
- Job Client keeps polling the Job Tracker for progress.
- Each child process reports its progress to parent task tracker.
- If a task reports progress, it sets a flag to indicate the status change that sent to the Task Tracker.
- The flag is verified in a separate thread for every 3 seconds and it notifies the Task Tracker of the current task status if set.
- Task tracker sends its progress to Job Tracker over the heartbeat for every five seconds.
- Job Tracker consolidate the task progress from all task trackers and keeps a holistic view of job.
- The Job receives the latest status by polling the Job Tracker every second.
Job Completion -
Once the job completed, the clean-up task will get processed like below -
- Once the task completed, Task Tracker sends the job completion status to the Job Tracker.
- Job Tracker then send the job completion message to client.
- Job Tracker cleans up its current working state for the job and instructs Task Trackers to perform the same and also cleans up all the temporary directories.
- The total process causes Job Client’s waitForJobToComplete method to return.