
Hive Architecture
The Hive Architecture describes the different parts that make Hive work and how they interact with each other. Hive has different components like the User Interface, Driver, Compiler, Metastore, and Execution Engine.
Each of these components plays an important role in processing your Hive queries. The main purpose of Hive is to translate your SQL-like queries into MapReduce jobs that run on Hadoop in the background. As a user, we don't need to worry about the technical details of MapReduce—Hive takes care of it for us.

User Interface (UI)
- The User Interface is where we interact with Hive.
- We can use different types of interfaces like Command Line Interface (CLI), Web UI, or JDBC/ODBC clients.
- Through the UI, we write HiveQL (which is similar to SQL) to interact with our data.
Driver
- The Driver is like the traffic controller in Hive.
- The Driver receives the HiveQL command and checks its correctness.
- It creates a session and manages how that query flows through the system.
Compiler
- The Compiler is like the translator in Hive’s architecture.
- The Compiler checks the syntax of your query (did you write it correctly?).
- It then converts the query into an Abstract Syntax Tree (AST) and later into an execution plan.
- The Compiler also interacts with the Metastore to get information about tables, columns, and data types.
Metastore
- The Metastore is like Hive’s memory or brain—it stores all the important information about the databases and tables.
- It keeps track of table names, columns, partitions, and storage locations.
- Metastore is essential because Hive depends on it to know where to find the data you’re querying.
- It uses a traditional Relational Database (like MySQL or Derby) in the background to store this metadata.
Execution Engine
- The Execution Engine is the worker in the Hive system.
- Once the Compiler has created the execution plan, the Execution Engine takes over.
- It converts the plan into MapReduce jobs or uses other engines like Tez or Spark to process the data.
- The Execution Engine also communicates with Hadoop’s Job Tracker and Task Trackers to run the jobs.
- In the end, it gathers the results and sends them back to the Driver, which then gives them to you.
Hadoop Distributed File System (HDFS)
- Even though this is not part of Hive itself, HDFS is where the actual data lives.
- Tables in Hive are just structured views of files stored in HDFS.
Hive interaction with Hadoop -
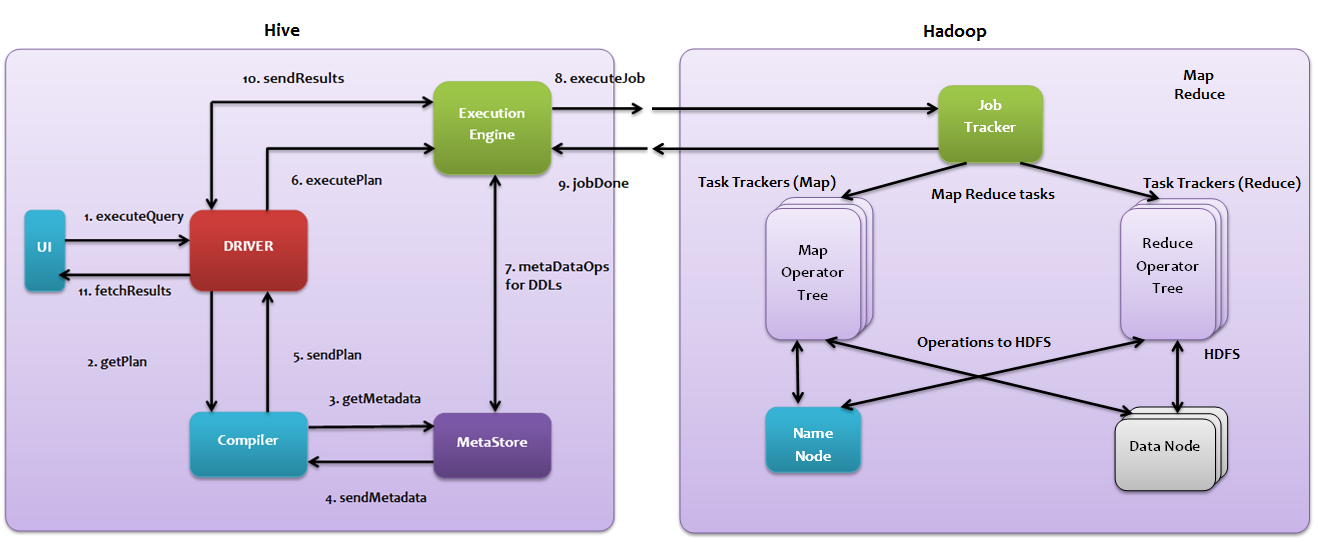
| Sequence | Operation | Description |
|---|---|---|
| 1 | executeQuery | The Query submitted from User Interface |
| 2 | getPlan | The driver passes the query to compiler to check syntax of the query and query plan of the query |
| 3 | getMetaData | The compiler sends the request to metastore |
| 4 | sendMetaData | Metastore sends the metadata to the compiler |
| 5 | sendPlan | Compiler verifies the requirement and sends the plan to driver |
| 6 | executePlan | Driver send the execution plan to execution engine |
| 7 | metaDataOps for DDLs | Execution engine gets the Metadata DDLs for table data from METASOTRE if required |
| 8 | executeJob | Execution Engine sends the job to JOB TRACKER and JOB Tracker will execute the job |
| 9 | jobDone | JOB TRACKER sends the jobDone Status to EXECUTION ENGINE along with the job output |
| 10 | sendResults | EXECUTION ENGINE sends the results to DRIVER |
| 11 | fetchResults | UI will fetch the results from DRIVER |
Example -
Let’s say you write this Hive query:
SELECT department, COUNT(*)
FROM employee_data
GROUP BY department;Here’s what happens step by step:
- User Interface: You submit the query through Hive CLI or a web interface.
- Driver: The Driver receives the query and creates a session.
- Compiler: The Compiler checks the syntax and creates an execution plan.
- Metastore: The Compiler asks the Metastore for table information (like where employee_data is stored).
- Execution Engine: The Engine runs the MapReduce job (or Tez/Spark job) on Hadoop.
- HDFS: The Engine reads and processes the data stored in HDFS.
- Driver: The results are collected and returned to you via the UI.
In the end, you see the department-wise count of employees.