
Hadoop MapReduce
MapReduce is a framework that allows us to write applications for processing vast amounts of data in parallel on large clusters of commodity hardware, all in a reliable manner.
What is MapReduce?
MapReduce is a processing technique and programming model for distributed computing based on Java. The MapReduce algorithm consists of two main tasks: Map and Reduce. The Map task takes a set of data and transforms it into another set, breaking individual elements down into tuples (key/value pairs). Next, the Reduce task takes the output from the Map task as input and combines those data tuples into a smaller set. As the name MapReduce suggests, the Reduce task is always performed after the Map task.
In the MapReduce model, the components responsible for data processing are known as mappers and reducers. While decomposing a data processing application into mappers and reducers can sometimes be complex, once the application is structured in the MapReduce format, scaling it to run on hundreds, thousands, or even tens of thousands of machines within a cluster is simply a matter of configuration. This straightforward scalability has attracted many programmers to adopt the MapReduce model.
The Algorithm -
- MapReduce is a way to process data where it is stored.
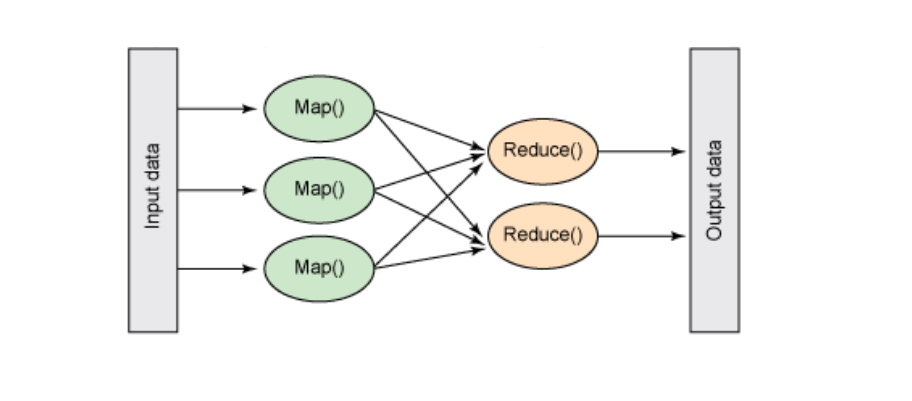
A MapReduce program has three main stages: the map stage, the shuffle stage, and the reduce stage.
- Map Stage: In this stage, mappers handle the input data, which is usually in files or directories saved in the Hadoop Distributed File System (HDFS). The program sends the input file to the mapper line by line. The mapper processes the data and creates small pieces of information.
- Shuffle and Reduce Stage: The reducers take the data from the mappers and process it. After this, they produce new outputs, which are saved in HDFS.
- During a MapReduce job, Hadoop sends the map and reduce tasks to the right servers in the cluster.
- The framework manages how data moves, checks if tasks are done, and controls data transfer between the cluster nodes.
- Most processing happens on nodes that have the necessary data on their local disks, which helps reduce network traffic.
- After finishing all tasks, the cluster gathers and reduces the output data, creating a clear result that is sent back to the Hadoop server.
Terminology -
- DataNode - A DataNode is where data is stored prior to any processing.
- Job - A job is defined as the execution of a Mapper and Reducer across a dataset.
- JobTracker - The JobTracker schedules jobs and monitors the assigned tasks to Task Trackers.
- Mapper - The Mapper converts input key/value pairs into a set of intermediate key/value pairs.
- MasterNode - This node runs the JobTracker and accepts job requests from clients.
- NamedNode - This is the node that manages the Hadoop Distributed File System (HDFS).
- PayLoad - Applications implement the Map and Reduce functions, forming the core of the job.
- SlaveNode - A SlaveNode is where the Map and Reduce programs are executed.
- Task Tracker - This component tracks tasks and reports their status back to the JobTracker.
- Task - A task refers to the execution of either a Mapper or a Reducer on a specific slice of data.
- Task Attempt - A task attempt is a specific instance of trying to execute a task on a SlaveNode.
Example -
Now that we have a fundamental understanding of MapReduce, let’s examine the code for the word count program using MapReduce.
Input Data
Welcome to TutorialsCampus Hello I am Developer at TutorialsCampus
Example Program -
import java.io.IOException;
import java.util.StringTokenizer;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class WordCount {
public static class TokenizerMapper extends Mapper<LongWritable, Text,Text,IntWritable>{
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
private LongWritable key = new LongWritable();
public void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String line = value.toString();
String[] words = line.split("\\s+");
for(String wordStr : words)
{
word.set(wordStr.trim());
if(!word.toString().isEmpty())
{
context.write(word, count);
}
}
}
}
public static class IntSumReducer
extends Reducer<Text,IntWritable,Text,IntWritable> {
private IntWritable result = new IntWritable();
public void reduce(Text key, Iterable<IntWritable> values,Context context) throws IOException, InterruptedException {
int sum = 0;
for (IntWritable val : values) {
sum += val.get();
}
result.set(sum);
context.write(key, result);
}
}
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
Job job = Job.getInstance(conf, "word count");
job.setJarByClass(WordCount.class);
job.setMapperClass(TokenizerMapper.class);
job.setCombinerClass(IntSumReducer.class);
job.setReducerClass(IntSumReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
FileInputFormat.addInputPath(job, new Path("/input"));
FileOutputFormat.setOutputPath(job, new Path("/output"));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}Save the above program as Processcounts.java. The compilation and execution of the program is explained below -
Compilation and Execution of Process Counts Program -
Let us assume we are in the home directory of a Hadoop user (e.g. /home/hadoop). Follow the steps given below to compile and execute the above program.
Step 1- The following command is to create a directory to store the compiled java classes.
$ mkdir counts Step 2- Download Hadoop-core-1.2.1.jar, which is used to compile and execute the MapReduce program. Let us assume the downloaded folder is /home/hadoop/.
Step 3- The following commands are used for compiling the Processcounts.java program and creating a jar for the program.
$ javac -classpath hadoop-core-1.2.1.jar -d counts Processcounts.java
$ jar -cvf counts.jar -C counts/Step 4- The following command is used to create an input directory in HDFS.
$HADOOP_HOME/bin/hadoop fs -mkdir input_dir Step 5- The following command is used to copy the input file named sample.txtin the input directory of HDFS.
$HADOOP_HOME/bin/hadoop fs -put /home/hadoop/sample.txt input_dirStep 6- The following command is used to verify the files in the input directory.
$HADOOP_HOME/bin/hadoop fs -ls input_dir/Step 7- The following command is used to run the Eleunit_max application by taking the input files from the input directory.
$HADOOP_HOME/bin/hadoop jar counts.jar hadoop.Processcounts input_dir output_dirWait for a while until the file is executed. After execution, as shown below, the output will contain the number of input splits, the number of Map tasks, the number of reducer tasks, etc.
Step 8- The following command is used to verify the resultant files in the output folder.
$HADOOP_HOME/bin/hadoop fs -ls output_dir/Step 9- The following command is used to see the output in Part-00000 file. This file is generated by HDFS.
$HADOOP_HOME/bin/hadoop fs -cat output_dir/part-00000Below is the output generated by the MapReduce program.
Welcome - 1 to - 1 TutorialsCampus - 2 Hello - 1 I - 1 am - 1 Developer - 1
Step 10- The following command is used to copy the output folder from HDFS to the local file system for analyzing.
$HADOOP_HOME/bin/hadoop fs -cat output_dir/part-00000/bin/hadoop dfs get output_dir /home/hadoop